Example of running level 2 processing steps
In this notebook, the following steps are performed:
Acquire, decimate, convert the data
[1]:
# Import relevant modules from the earscopestraintools package
from earthscopestraintools.mseed_tools import ts_from_mseed
from earthscopestraintools.gtsm_metadata import GtsmMetadata
from earthscopestraintools.timeseries import plot_timeseries_comparison
# Allow logged output to be printed in the notebook as code cells are run
import logging
logger = logging.getLogger()
logging.basicConfig(
format="%(message)s", level=logging.INFO
)
Acquire, decimate, convert the data from raw
Download 1hz raw data (in counts) from the IRIS/EarthScope DMC
This step also removes instrumental calibration pulses (999999 values in the raw data that occurr periodically).
Downsample to 300s
Applies a low-pass, minimum-phase finite impulse response filter (Hodgkinson and Agnew, 2007) prior to decimating the timeseries. Note that coseismic steps can not be relieably determined from the filtered data. Longer period signals are accurately represented.
Convert the data to microstrain
Raw data (in counts) represents a unit of electrical measurment from the gauge capacitance bridge, related to the diameter of the gauge. The raw data is converted to microstrain via linearization.
See the introductory materials for more information and further resources
[2]:
# define the network and station using FDSN seed codes ()
# then load the metadata for that station
network = 'IV' # e.g. PB = Plate Boundary Observatory, IV = I
station = 'TSM5' # available stations listed here https://www.unavco.org/data/strain-seismic/bsm-data/lib/docs/bsm_metadata.txt
meta = GtsmMetadata(network,station)
# Print the metadata contents
meta.show()
network: IV
station: TSM5
latitude: 43.479691
longitude: 12.60252
gap: 0.0001
orientation (CH0EofN): 342.9
reference_strains:
{'linear_date': '2022:154', 'CH0': 50858593, 'CH1': 53668101, 'CH2': 53904388, 'CH3': 49946112}
strain_matrices:
lab:
[[ 0.2962963 0.51851852 0.2962963 0.22222222]
[-0.23421081 0.3334514 0.10083025 -0.20007084]
[-0.31429352 -0.1611967 0.3787722 0.09671802]]
ER2010:
None
KH2013:
None
CH2024:
[[-2.29756838 -1.78884499 -1.90750646 -0.23665333]
[-0.08233948 0.27250792 0.36601184 -0.13119797]
[-0.48265607 -0.38451238 -0.00899979 0.08270539]]
CH_prelim:
[[-2.29756838 -1.78884499 -1.90750646 -0.23665333]
[-0.08233948 0.27250792 0.36601184 -0.13119797]
[-0.48265607 -0.38451238 -0.00899979 0.08270539]]
EM2024:
[[-8.580e-05 -6.860e-05 -1.037e-04 1.330e-05]
[ 1.100e-06 1.620e-05 2.470e-05 -9.700e-06]
[-2.060e-05 -1.450e-05 -2.900e-06 9.300e-06]]
atmp_response:
{'CH0': -0.00737258, 'CH1': -0.00589086, 'CH2': -0.0060482, 'CH3': -0.00492305}
tidal_params:
{('CH0', 'M2', 'phz'): '31.841', ('CH0', 'M2', 'amp'): '14.321', ('CH0', 'M2', 'doodson'): '2 0 0 0 0 0', ('CH0', 'O1', 'phz'): '-168.061', ('CH0', 'O1', 'amp'): '7.432', ('CH0', 'O1', 'doodson'): '1-1 0 0 0 0', ('CH0', 'P1', 'phz'): '-167.671', ('CH0', 'P1', 'amp'): '3.415', ('CH0', 'P1', 'doodson'): '1 1-2 0 0 0', ('CH0', 'K1', 'phz'): '-167.543', ('CH0', 'K1', 'amp'): '10.201', ('CH0', 'K1', 'doodson'): '1 1 0 0 0 0', ('CH0', 'N2', 'phz'): '31.539', ('CH0', 'N2', 'amp'): '2.731', ('CH0', 'N2', 'doodson'): '2-1 0 1 0 0', ('CH0', 'S2', 'phz'): '32.589', ('CH0', 'S2', 'amp'): '6.708', ('CH0', 'S2', 'doodson'): '2 2-2 0 0 0', ('CH1', 'M2', 'phz'): '163.242', ('CH1', 'M2', 'amp'): '15.315', ('CH1', 'M2', 'doodson'): '2 0 0 0 0 0', ('CH1', 'O1', 'phz'): '-35.927', ('CH1', 'O1', 'amp'): '9.582', ('CH1', 'O1', 'doodson'): '1-1 0 0 0 0', ('CH1', 'P1', 'phz'): '-33.551', ('CH1', 'P1', 'amp'): '4.642', ('CH1', 'P1', 'doodson'): '1 1-2 0 0 0', ('CH1', 'K1', 'phz'): '-36.911', ('CH1', 'K1', 'amp'): '12.426', ('CH1', 'K1', 'doodson'): '1 1 0 0 0 0', ('CH1', 'N2', 'phz'): '162.041', ('CH1', 'N2', 'amp'): '2.618', ('CH1', 'N2', 'doodson'): '2-1 0 1 0 0', ('CH1', 'S2', 'phz'): '162.52', ('CH1', 'S2', 'amp'): '8.469', ('CH1', 'S2', 'doodson'): '2 2-2 0 0 0', ('CH2', 'M2', 'phz'): '-128.96', ('CH2', 'M2', 'amp'): '16.945', ('CH2', 'M2', 'doodson'): '2 0 0 0 0 0', ('CH2', 'O1', 'phz'): '114.849', ('CH2', 'O1', 'amp'): '7.556', ('CH2', 'O1', 'doodson'): '1-1 0 0 0 0', ('CH2', 'P1', 'phz'): '113.033', ('CH2', 'P1', 'amp'): '3.29', ('CH2', 'P1', 'doodson'): '1 1-2 0 0 0', ('CH2', 'K1', 'phz'): '111.636', ('CH2', 'K1', 'amp'): '9.288', ('CH2', 'K1', 'doodson'): '1 1 0 0 0 0', ('CH2', 'N2', 'phz'): '-129.457', ('CH2', 'N2', 'amp'): '3.315', ('CH2', 'N2', 'doodson'): '2-1 0 1 0 0', ('CH2', 'S2', 'phz'): '-128.404', ('CH2', 'S2', 'amp'): '7.693', ('CH2', 'S2', 'doodson'): '2 2-2 0 0 0', ('CH3', 'M2', 'phz'): '-17.446', ('CH3', 'M2', 'amp'): '13.994', ('CH3', 'M2', 'doodson'): '2 0 0 0 0 0', ('CH3', 'O1', 'phz'): '149.299', ('CH3', 'O1', 'amp'): '11.92', ('CH3', 'O1', 'doodson'): '1-1 0 0 0 0', ('CH3', 'P1', 'phz'): '148.609', ('CH3', 'P1', 'amp'): '4.776', ('CH3', 'P1', 'doodson'): '1 1-2 0 0 0', ('CH3', 'K1', 'phz'): '149.549', ('CH3', 'K1', 'amp'): '14.392', ('CH3', 'K1', 'doodson'): '1 1 0 0 0 0', ('CH3', 'N2', 'phz'): '-20.857', ('CH3', 'N2', 'amp'): '2.463', ('CH3', 'N2', 'doodson'): '2-1 0 1 0 0', ('CH3', 'S2', 'phz'): '-15.441', ('CH3', 'S2', 'amp'): '7.447', ('CH3', 'S2', 'doodson'): '2 2-2 0 0 0'}
detrend_params:
{'CH0': {'F': '0.0', 'A1': '0.0', 'T1': '0.0', 'M': '0.0', 'A2': '0.0', 'T2': '0.0'}, 'CH1': {'F': '0.0', 'A1': '0.0', 'T1': '0.0', 'M': '0.0', 'A2': '0.0', 'T2': '0.0'}, 'CH2': {'F': '0.0', 'A1': '0.0', 'T1': '0.0', 'M': '0.0', 'A2': '0.0', 'T2': '0.0'}, 'CH3': {'F': '0.0', 'A1': '0.0', 'T1': '0.0', 'M': '0.0', 'A2': '0.0', 'T2': '0.0'}, 'detrend_date': '2022-06-03T00:00:00'}
[3]:
# Provide the start and end times for analysis
start="2023-01-01T00:00:00"
end = "2023-01-10T00:00:00"
# ts_from_mseed will load data into a earthscopestraintools.timeseres.Timeseries object via obspy and dataselect
# The location and channel codes follow SEED format
strain_raw = ts_from_mseed(network=network, station=station, location='T0', channel='LS*', start=start, end=end)
# Print some stats and plot the data
strain_raw.stats()
strain_raw.plot(type='line')
IV TSM5 Loading T0 LS* from 2023-01-01T00:00:00 to 2023-01-10T00:00:00 from Earthscope DMC miniseed
Trace 1. 2023-01-01T00:00:00.000000Z:2023-01-10T00:00:00.000000Z mapping LS1 to CH0
Trace 2. 2023-01-01T00:00:00.000000Z:2023-01-10T00:00:00.000000Z mapping LS2 to CH1
Trace 3. 2023-01-01T00:00:00.000000Z:2023-01-10T00:00:00.000000Z mapping LS3 to CH2
Trace 4. 2023-01-01T00:00:00.000000Z:2023-01-10T00:00:00.000000Z mapping LS4 to CH3
Found 0 epochs with nans, 5.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Converting 999999 gap fill values to nan
Found 5 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
IV.TSM5.T0.LS*
| Channels: ['CH0', 'CH1', 'CH2', 'CH3']
| TimeRange: 2023-01-01 00:00:00 - 2023-01-10 00:00:00 | Period: 1.0s
| Series: raw| Units: counts| Level: 0| Gaps: 0.0%
| Epochs: 777601| Good: 777596.0| Missing: 5.0| Interpolated: 0.0
| Samples: 3110404| Good: 3110384| Missing: 20| Interpolated: 0

[4]:
# Let's look at all available attributes and functions of strain_raw
# All classes and functions can be analyzed in this way
print('Attributes:')
for var in vars(strain_raw).keys():
print(f" {var}")
Attributes:
data
columns
quality_df
period
series
units
level
network
station
name
nans
nines
epochs
gap_percentage
[5]:
functs = [func for func in dir(strain_raw) if callable(getattr(strain_raw,func)) and func.startswith('__') == False]
print('Functions')
for funct in functs:
print(f" {funct}")
Functions
_infer_period
_set_initial_level_flags
_set_initial_quality_flags
_set_initial_version
append
apply_calibration_matrix
apply_corrections
baytap_analysis
butterworth_filter
calculate_magnitude
calculate_offsets
calculate_pressure_correction
calculate_tide_correction
check_for_gaps
decimate_1s_to_300s
decimate_to_hourly
double_exponential_trend_correction
dynamic_strain
get_eig
interpolate
linear_trend_correction
linearize
plot
remove_fill_values
save_csv
set_data
set_local_tdb_uri
set_s3_tdb_uri
set_units
show_flagged_data
show_flags
stats
strain_video
truncate
[6]:
# Use one of the functions to filter and decimate: calculate a 300s decimated Timeseries of raw counts
decimated_counts = strain_raw.decimate_1s_to_300s()
decimated_counts.data.head()
Decimating to 300s
Interpolating data using method=linear and limit=3600
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
[6]:
| CH0 | CH1 | CH2 | CH3 | |
|---|---|---|---|---|
| time | ||||
| 2023-01-01 00:00:00 | 45325335.0 | 55394828.0 | 54709901.0 | 45262210.0 |
| 2023-01-01 00:05:00 | 45325331.0 | 55394829.0 | 54709890.0 | 45262207.0 |
| 2023-01-01 00:10:00 | 45325301.0 | 55394831.0 | 54709844.0 | 45262174.0 |
| 2023-01-01 00:15:00 | 45325293.0 | 55394839.0 | 54709801.0 | 45262134.0 |
| 2023-01-01 00:20:00 | 45325328.0 | 55394853.0 | 54709769.0 | 45262104.0 |
[7]:
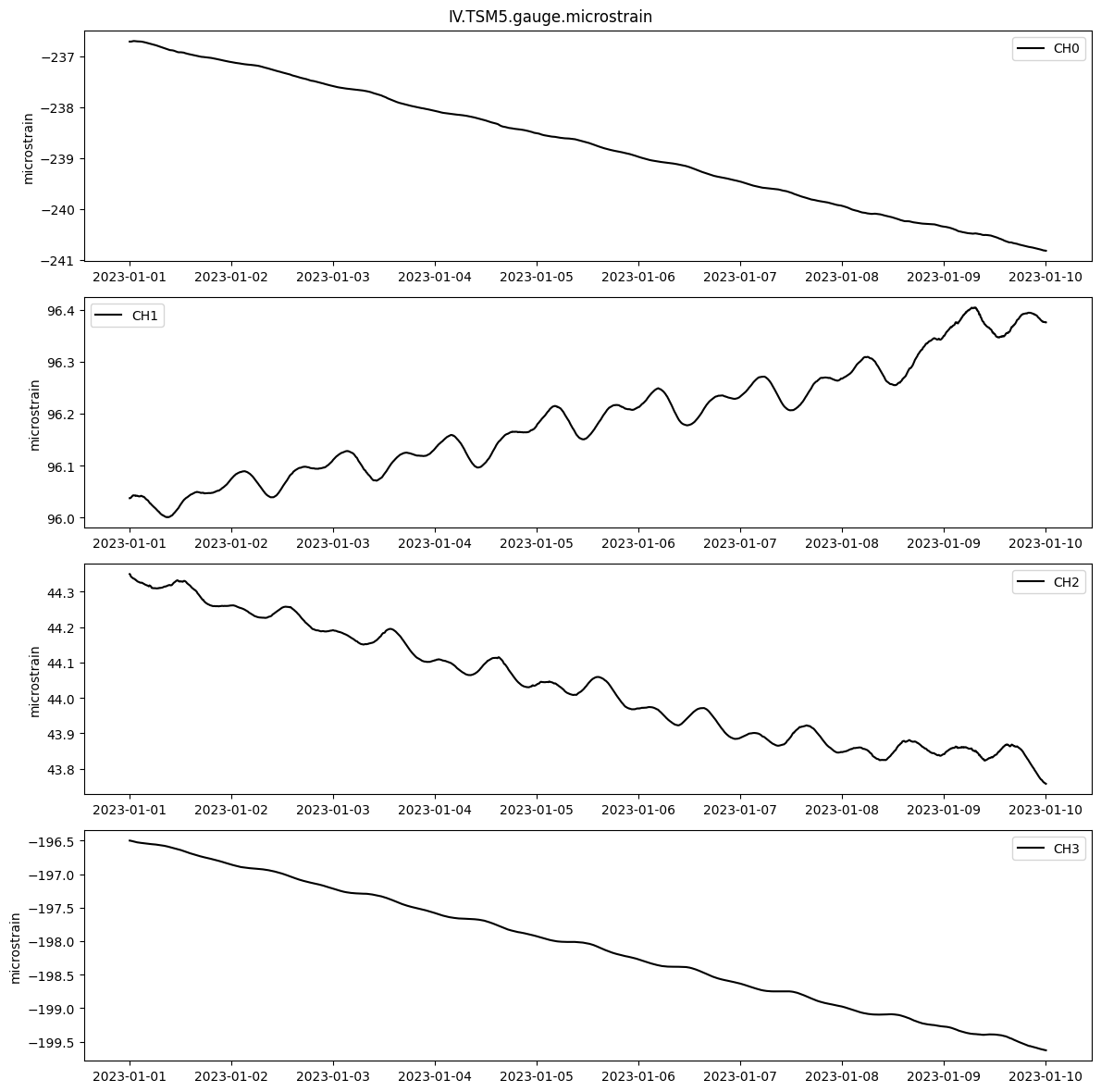
# Convert the raw counts into units of microstrain (1E-06)
name = f"{network}.{station}.gauge.microstrain" # Plot name
# The reference strains are standard values, but to zero to the first values of the time series, try:
# reference_strains=decimated_counts.data.values[0]
gauge_microstrain = decimated_counts.linearize(reference_strains=meta.reference_strains, gap=meta.gap, name=name)
gauge_microstrain.stats()
gauge_microstrain.plot()
gauge_microstrain.data.head()
Converting raw counts to microstrain
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
IV.TSM5.gauge.microstrain
| Channels: ['CH0', 'CH1', 'CH2', 'CH3']
| TimeRange: 2023-01-01 00:00:00 - 2023-01-10 00:00:00 | Period: 300s
| Series: microstrain| Units: microstrain| Level: 1| Gaps: 0.0%
| Epochs: 2593| Good: 2592.25| Missing: 0.75| Interpolated: 0.0
| Samples: 10372| Good: 10369| Missing: 3| Interpolated: 0
[7]:
| CH0 | CH1 | CH2 | CH3 | |
|---|---|---|---|---|
| time | ||||
| 2023-01-01 00:00:00 | -236.716184 | 96.037116 | 44.349675 | -196.500414 |
| 2023-01-01 00:05:00 | -236.716337 | 96.037173 | 44.349059 | -196.500530 |
| 2023-01-01 00:10:00 | -236.717491 | 96.037289 | 44.346481 | -196.501795 |
| 2023-01-01 00:15:00 | -236.717799 | 96.037751 | 44.344072 | -196.503330 |
| 2023-01-01 00:20:00 | -236.716453 | 96.038560 | 44.342279 | -196.504481 |
Corrections
Trend
A simple linear trend is calculated for this example to remove the long-term borehole relaxation signal.
[8]:
# calculate a linear trend correction and store it as a Timeseries
name = f"{network}.{station}.gauge.trend_c"
trend_c = gauge_microstrain.linear_trend_correction(name=name) # simple least squares trend
# create a trend corrected Timeseries
corrected = gauge_microstrain.apply_corrections([trend_c])
# compare uncorrected, trend correction, and trend corrected Timeseries
plot_timeseries_comparison([gauge_microstrain, trend_c, corrected], names=['uncorrected', 'trend', 'corrected'], zero=True)
Calculating linear trend correction
Trend Start: 2023-01-01 00:00:00
Trend End: 2023-01-10 00:00:00
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Applying corrections
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%

Tides
The tidal amplitudes and phases for many of the largest tidal constituents (M2, O1, P1, K1, N2, S2) have been pre-determined for the stations in BAYTAP08, a Bayesian modelling procedure. These constituents are fed to SPOTL to create a forward model timeseries of tides for each gauge, which can then be removed from the data.
[9]:
# This step will run a docker container of SPOTL (https://igppweb.ucsd.edu/~agnew/Spotl/spotlmain.html) to calculate the tides.
# If docker is not running on your computer, start docker.
name = f"{network}.{station}.gauge.tide_c"
tide_c = gauge_microstrain.calculate_tide_correction(tidal_parameters=meta.tidal_params, longitude=meta.longitude, name=name)
tide_c.plot()
#tide_corrected = gauge_microstrain.apply_corrections([tide_c])
#plot_timeseries_comparison([gauge_microstrain, tide_corrected], names=['uncorrected', 'atmp_corrected'], zero=True)
Calculating tide correction
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%

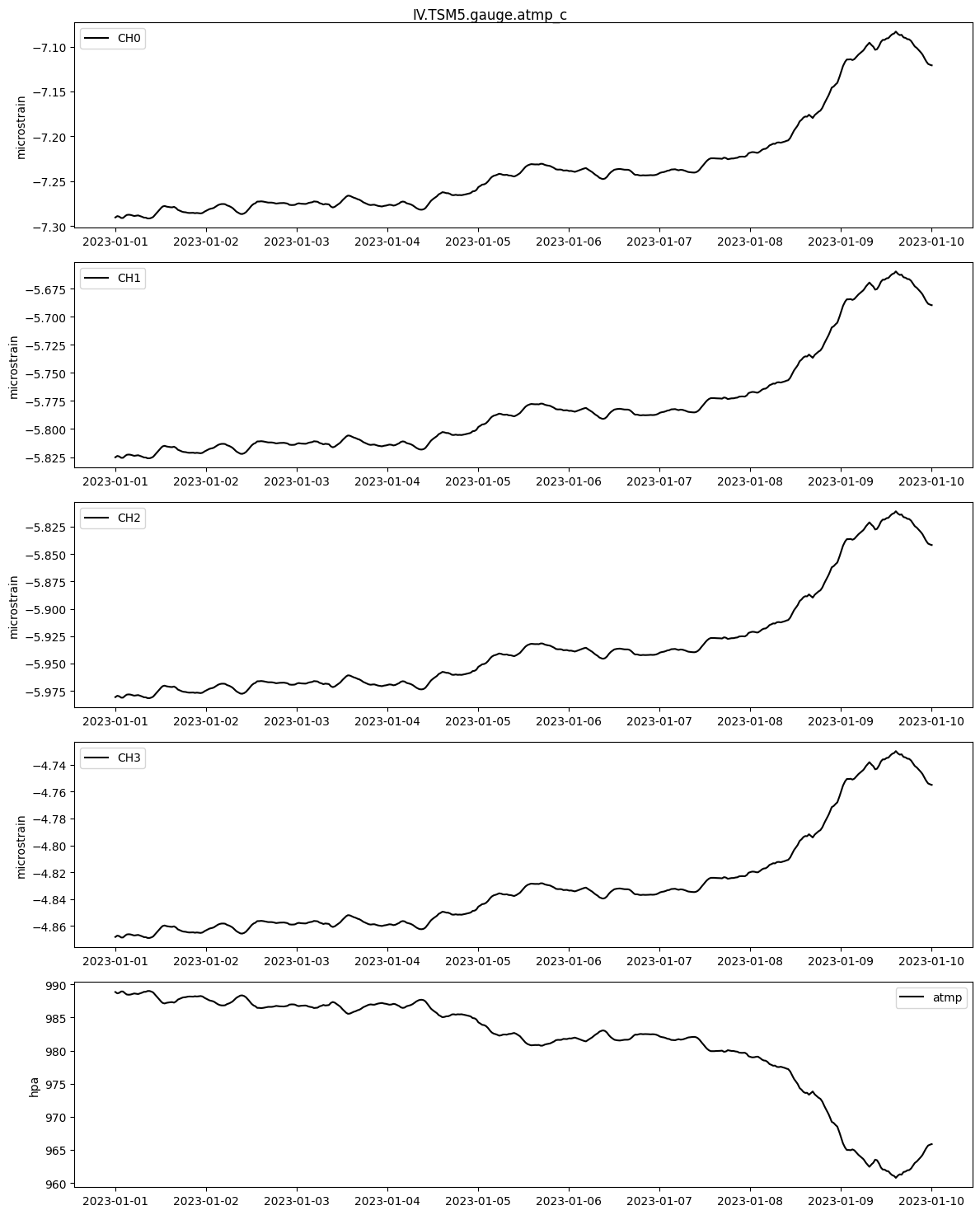
Atmospheric Pressure
An atmospheric pressure correction coefficient, similar to the tidal constituents, was likewise calculated for each gauge in BAYTAP08. This coefficient is multiplied by the colocated surface barometric pressure sensor data to calculate a pressure correction time series. Note that many stations have pressure data at a sample period of 30 minutes, while some have 1 sps data available. In the case of 30 minute data, the correction can be linearly interpolated to the time series of interest.
[10]:
# Acquire pressure data, calculate and plot the correction
# Pressure data from miniseed
# note that channel code for 1 sps data, if available, is 'LDO'
atmp_raw = ts_from_mseed(network=network, station=station, location='*', channel='RDO',
start=start, end=end, period=60*30, scale_factor=0.001, units='hpa')
# Interpolate the pressure data to the same time as the strain data
atmp = atmp_raw.interpolate(new_index=strain_raw.data.index, series='hpa')
# Calculate and plot the correction
name = f"{network}.{station}.gauge.atmp_c"
atmp_c = atmp.calculate_pressure_correction(meta.atmp_response, name=name)
atmp_c.plot(atmp=atmp)
# Plot the corrected time series comparison if desired
#atmp_corrected = gauge_microstrain.apply_corrections([atmp_c])
#atmp_corrected.plot()
#plot_timeseries_comparison([gauge_microstrain, atmp_corrected], names=['uncorrected', 'atmp_corrected'], zero=True)
IV TSM5 Loading * RDO from 2023-01-01T00:00:00 to 2023-01-10T00:00:00 from Earthscope DMC miniseed
Trace 1. 2023-01-01T00:00:00.000000Z:2023-01-10T00:00:00.000000Z mapping RDO to atmp
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Converting 999999 gap fill values to nan
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Interpolating data using method=linear and limit=3600
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Calculating pressure correction
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Offsets
Offsets in this section are automatically detected via a simple first differencing algorithm. The best approach is to first correct for other known changes (tides, pressure, trend), then to apply the calculate_offsets function. This function finds jumps between consecutive datapoints that are above a cutoff limit, which is assigned from a user-specified value multiplied by a user-specified percentile of all first differences calculated for the gauge. For example, if a multiplier of 10 and
percentile of 75% are used on a dataset whose first difference 75th percentile is 2 nanostrain, any jump in the data above 20 nanostrain will be flagged as an offset. This method is not perfect, but works well for certain situations.
[11]:
# Calculate offset correction on data that has been corrected for tides, trend, and pressure
name = f"{network}.{station}.gauge.offset_c"
pre_offset_corrected = gauge_microstrain.apply_corrections([tide_c,trend_c]) #, atmp_c])
offset_c = pre_offset_corrected.calculate_offsets(limit_multiplier=5,cutoff_percentile=75,name=name)
offset_c.plot()
Applying corrections
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Calculating offsets using cutoff percentile of 75 and limit multiplier of 5.
Using offset limits of [0.002303, 0.001166, 0.00148, 0.000992]
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%

Plot corrections
[12]:
title=f"{network}.{station}"
gauge_corrected = gauge_microstrain.apply_corrections([tide_c, atmp_c, offset_c, trend_c])
plot_timeseries_comparison([gauge_microstrain, gauge_corrected], title=title, names=['uncorrected', 'corrected'], zero=True)
Applying corrections
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
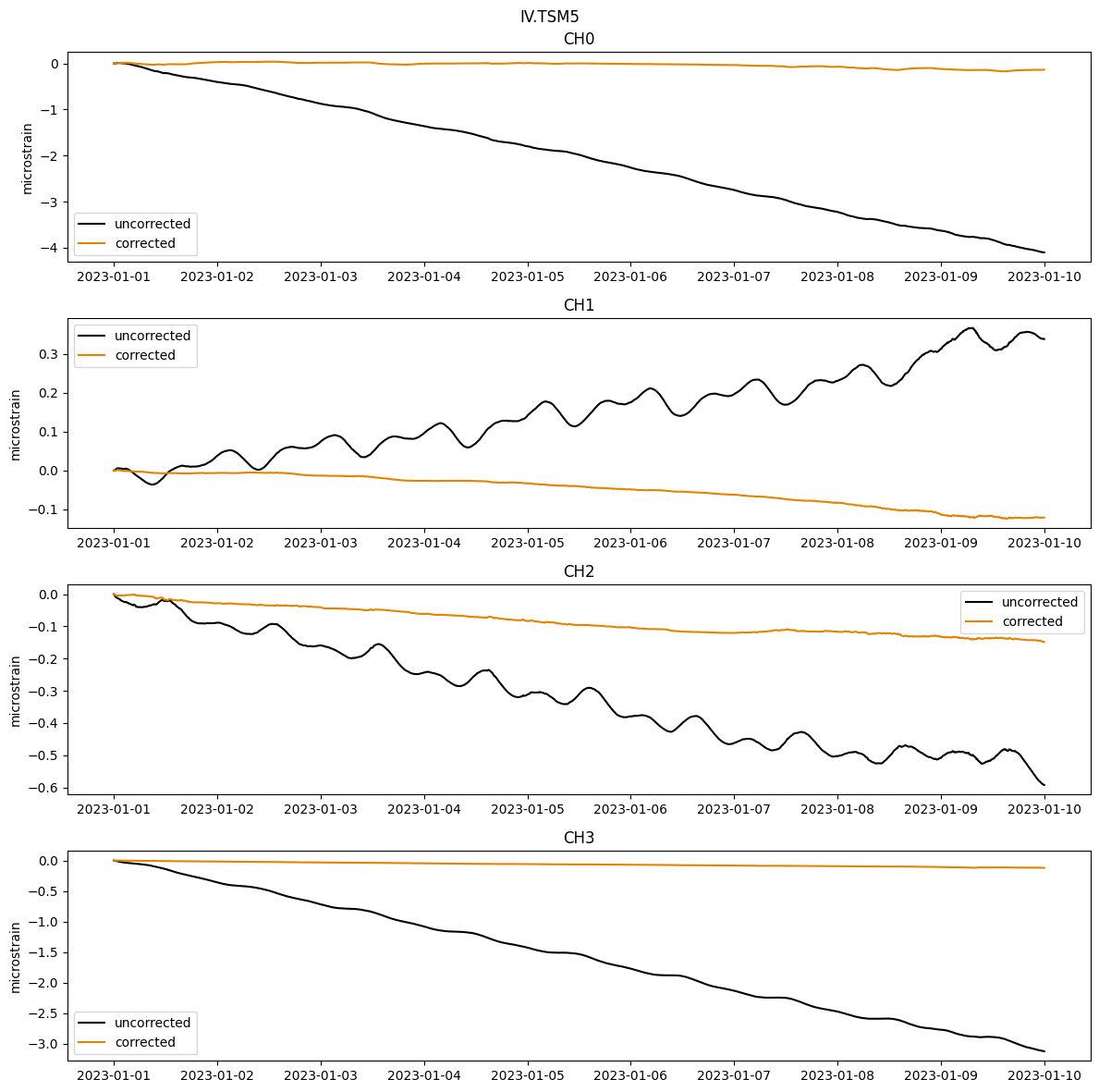
Regional Strain Conversion
The strain from each individual gauge represents the whole instrument, grout, and bedrock response to strain. Most geophysical applications are interested in only the value of rock formation strain. To this end, we apply a calibration (or orientation) matrix to the four gauge strains that transforms the recorded gauge strains into regional areal, differential shear, and engineering shear strains in the East/North reference system.
Various methods for calibration have been completed, and the background information in the docs provides references if you’d like to learn more about each type of calibration. All stations have a ‘lab’ orientation matrix, which relies on accurate installation orientations for the gauges, equal gauge sensitivities, isotropic and homogeneous rock conditions, and rock strength comparable to that of granite (Hodgkinson et al., 2013). Regional strains can also be achieved through tidal calibration, which compares the observed tidal signal to predicted, approximately well-known tidal signal. Tidal calibrations are available for several stations from calibrations completed by geoscience community members (Hanagan et al., In Prep; Hodgkinson et al., 2013; Roeloffs et al., 2010). The best calibration should be assesed on an individual station basis.
[13]:
# Which orientation matrices are available for the station?
meta.strain_matrices
[13]:
{'lab': array([[ 0.2962963 , 0.51851852, 0.2962963 , 0.22222222],
[-0.23421081, 0.3334514 , 0.10083025, -0.20007084],
[-0.31429352, -0.1611967 , 0.3787722 , 0.09671802]]),
'ER2010': None,
'KH2013': None,
'CH2024': array([[-2.29756838, -1.78884499, -1.90750646, -0.23665333],
[-0.08233948, 0.27250792, 0.36601184, -0.13119797],
[-0.48265607, -0.38451238, -0.00899979, 0.08270539]]),
'CH_prelim': array([[-2.29756838, -1.78884499, -1.90750646, -0.23665333],
[-0.08233948, 0.27250792, 0.36601184, -0.13119797],
[-0.48265607, -0.38451238, -0.00899979, 0.08270539]]),
'EM2024': array([[-8.580e-05, -6.860e-05, -1.037e-04, 1.330e-05],
[ 1.100e-06, 1.620e-05, 2.470e-05, -9.700e-06],
[-2.060e-05, -1.450e-05, -2.900e-06, 9.300e-06]])}
[15]:
# Choose calibration matrix and calculare regional strains
matrix_name = "CH2024"
calibration_matrix = meta.strain_matrices[matrix_name]
regional_microstrain = gauge_microstrain.apply_calibration_matrix(calibration_matrix, calibration_matrix_name=matrix_name)
regional_microstrain.stats()
regional_microstrain.plot()
Applying CH2024 matrix:
[[-2.29756838 -1.78884499 -1.90750646 -0.23665333]
[-0.08233948 0.27250792 0.36601184 -0.13119797]
[-0.48265607 -0.38451238 -0.00899979 0.08270539]]
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
IV.TSM5.gauge.microstrain.calibrated
| Channels: ['Eee+Enn.CH2024', 'Eee-Enn.CH2024', '2Ene.CH2024']
| TimeRange: 2023-01-01 00:00:00 - 2023-01-10 00:00:00 | Period: 300s
| Series: microstrain| Units: microstrain| Level: 2a| Gaps: 0.0%
| Epochs: 2593| Good: 2590.0| Missing: 3.0| Interpolated: 0.0
| Samples: 7779| Good: 7770| Missing: 9| Interpolated: 0

[16]:
# Calculate regional strain corrections
regional_tide_c = tide_c.apply_calibration_matrix(calibration_matrix, calibration_matrix_name=matrix_name)
regional_trend_c = trend_c.apply_calibration_matrix(calibration_matrix, calibration_matrix_name=matrix_name)
regional_atmp_c = atmp_c.apply_calibration_matrix(calibration_matrix, calibration_matrix_name=matrix_name)
regional_offset_c = offset_c.apply_calibration_matrix(calibration_matrix, calibration_matrix_name=matrix_name)
Applying CH2024 matrix:
[[-2.29756838 -1.78884499 -1.90750646 -0.23665333]
[-0.08233948 0.27250792 0.36601184 -0.13119797]
[-0.48265607 -0.38451238 -0.00899979 0.08270539]]
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Applying CH2024 matrix:
[[-2.29756838 -1.78884499 -1.90750646 -0.23665333]
[-0.08233948 0.27250792 0.36601184 -0.13119797]
[-0.48265607 -0.38451238 -0.00899979 0.08270539]]
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Applying CH2024 matrix:
[[-2.29756838 -1.78884499 -1.90750646 -0.23665333]
[-0.08233948 0.27250792 0.36601184 -0.13119797]
[-0.48265607 -0.38451238 -0.00899979 0.08270539]]
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Applying CH2024 matrix:
[[-2.29756838 -1.78884499 -1.90750646 -0.23665333]
[-0.08233948 0.27250792 0.36601184 -0.13119797]
[-0.48265607 -0.38451238 -0.00899979 0.08270539]]
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
[17]:
# Plot regional strains
title=f"{network}.{station}"
regional_corrected = regional_microstrain.apply_corrections([regional_tide_c, regional_atmp_c, regional_offset_c, regional_trend_c])
regional_corrected.plot()
plot_timeseries_comparison([regional_microstrain, regional_corrected], title=title, names=['uncorrected', 'corrected'], zero=True)
Applying corrections
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%


Additional Comparisons:
Plot corrected data with other environmental data
Rainfall and more general water level changes can induce strain changes. Rain gauges at all stations, and pore pressure transducers at some stations, provide useful hyrologic information for comparison to the strain time series.
[18]:
# Get rain data and convert to units of mm per 30 minute sample period
rainfall = ts_from_mseed(network=network, station=station, location='*', channel='RRO',
start=start, end=end, period=60*30, scale_factor=0.0001, units='mm/30m')
regional_corrected.plot(rainfall=rainfall)
regional_corrected.stats()
IV TSM5 Loading * RRO from 2023-01-01T00:00:00 to 2023-01-10T00:00:00 from Earthscope DMC miniseed
Trace 1. 2023-01-01T00:00:00.000000Z:2023-01-10T00:00:00.000000Z mapping RRO to rain
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
Converting 999999 gap fill values to nan
Found 0 epochs with nans, 0.0 epochs with 999999s, and 0 missing epochs.
Total missing data is 0.0%
IV.TSM5.gauge.microstrain.calibrated.corrected
| Channels: ['Eee+Enn.CH2024', 'Eee-Enn.CH2024', '2Ene.CH2024']
| TimeRange: 2023-01-01 00:00:00 - 2023-01-10 00:00:00 | Period: 300s
| Series: corrected| Units: microstrain| Level: 2a| Gaps: 0.0%
| Epochs: 2593| Good: 2590.0| Missing: 3.0| Interpolated: 0.0
| Samples: 7779| Good: 7770| Missing: 9| Interpolated: 0
